Intuition behind Power of 2 Choices Load balancing
One of the hardest parts of balancing load across many targets is keeping an accurate view of their load. We have to check all the targets; this is expensive. Also, the process of checking is not instantaneous, which leads to stale data which in turn causes request herding. What if we assign a request to a random target? This works surprisingly well but causes hotspots, which is not ideal. A variant of this is where we select 2 targets at random and then assign the request to the one with less load, which works even better. This is called the Power of 2 Choices balancing.
This has been studied in Maths as the Balls & Bins problem. Where we place balls into bins, where a bin can house any number of balls. From here, we get that the typical max load on a target is exponentially better with 2 choices, i.e. for random and for random choices, for 2 this will be . From this result, we can also see that going from 1 to 2 improvement is far better than selections of 3 or 4, which are only marginally better. But it is not obvious intuitively, since we are still selecting the two targets randomly. This same exponential gap underlies why data structures like cuckoo hashing work so well: having two random choices dramatically reduces collisions and spreads keys more evenly.
Here is a visualisation of how the Power of 2 choices approach perform better, as you can see in the gif, the load appears more uniform as the number of requests increases.
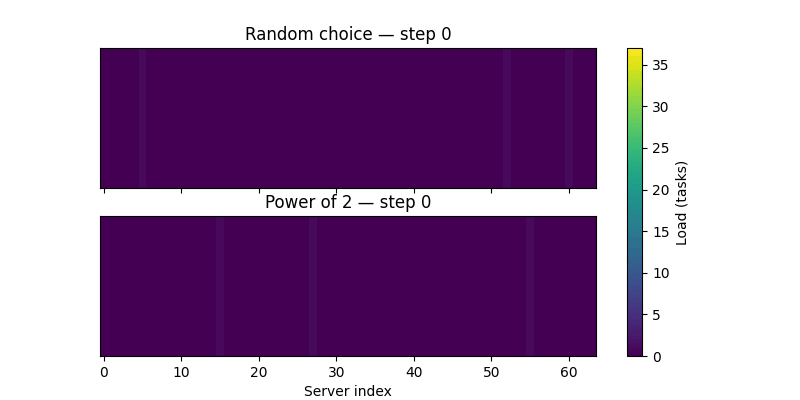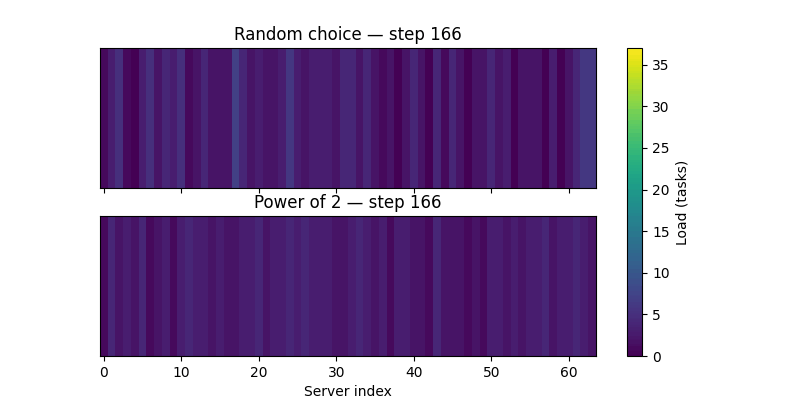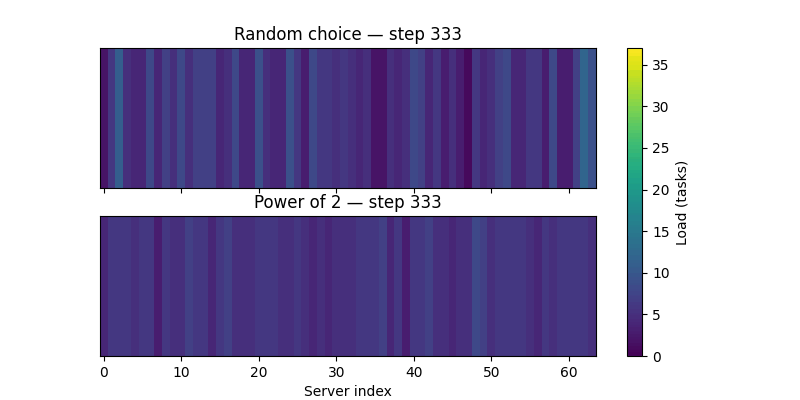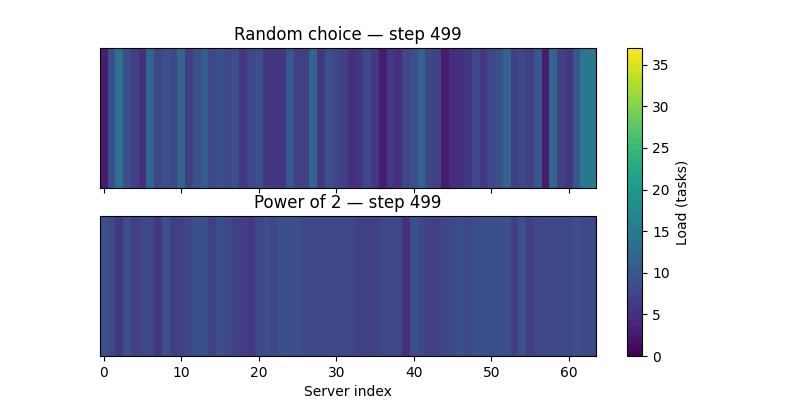
If you want to go deeper into the practical side of these tradeoffs, Tyler McCullen’s talk “Load Balancing is Impossible” and Mark Booker’s Blog Post are excellent resources.
I recently found a UWaterloo slide about this that had a very intuitive explanation of this. Say in our servers, servers are already at max load out of a total servers, say max load is . The probability that the max load grows is just since we can only choose one target. But when we get to choose two targets, what is the probability that the max load grows? What would it take to make ? We will have to choose two targets that are already at , since if only one is at , the other target will be selected, and max will not increase. Now, what is the probability that two targets are at max and we choose both of them is .
Here, would already be small. Furthermore to increase the max even more from to , the number of servers with max load would have fallen even more, call it , the probability will be which is event tinier than moving from to . This is why the tail of max load in case of 2 choices falls very rapidly, since with every iteration the probability of increasing the max falls faster than the single choice method.
Let’s go through with an example
- Say we have targets with a max of requests each, the probability of selecting two of these is .
- Now we should expect only targets to have the max requests, and then only targets with max requests
- This amounts to for a max of requests.
- To find the upper bound of at a fixed we can set the to the minimum . This will give us